█ 10.08.2010 00:31
В данной теме предлагаю задавать возможные вопросы по использованию надстройки Inventor: что нажать, какие параметры выбрать, что означает результат и т.д.
█ 22.08.2010 15:59
Цитата:
1. Андрей, наверное, в пояснение к каждому методу нужно описать как выбираются границы к АА и СС (я так понимаю, что ты описал только метод касательных в своем ответе). administrator
Спасибо за мнение, Вадим, мне это важно. Прошу заинтересованных лиц высказаться по данному вопросу.
2. АА получается путем разделения группы А с помощью еще одной касательной, которая параллельна прямой, проходящей через начало координат и точку А. С СС - аналогично.
Цитата:
1. Думал над этим в процессе разработки, но форма получилась бы огромной. К тому же, в АВС мне график кажется излишним, т.к. самый объективный метод - метод касательных - разделяет объекты на группы вне зависимости от того, что ты увидишь на графике и делает это правильно. Плюс после анализа распределение можно оценить по статистике в примечании. VVY Андрей, привет!
1. Хотел увидеть график в методе касательных, чтобы видеть реальность границ.
2. Хотел бы видеть пояснение к группам АА и СС. Что это и как это?
Кому данный вопрос также интересен, прошу меня поддержать.
1. Хотел увидеть график в методе касательных, чтобы видеть реальность границ.
2. Хотел бы видеть пояснение к группам АА и СС. Что это и как это?
Кому данный вопрос также интересен, прошу меня поддержать.
Спасибо за мнение, Вадим, мне это важно. Прошу заинтересованных лиц высказаться по данному вопросу.
2. АА получается путем разделения группы А с помощью еще одной касательной, которая параллельна прямой, проходящей через начало координат и точку А. С СС - аналогично.
2. Также, наверное, нужно написать что такое метод первой касательной и второй касательной в пояснении.
█ 23.08.2010 02:15
Цитата:
1. Не понял вопроса. Все 4 реализованных метода делятся на: VVY 1. Андрей, наверное, в пояснение к каждому методу нужно описать как выбираются границы к АА и СС (я так понимаю, что ты описал только метод касательных в своем ответе).
2. Также, наверное, нужно написать что такое метод первой касательной и второй касательной в пояснении.
2. Также, наверное, нужно написать что такое метод первой касательной и второй касательной в пояснении.
- те, в которых пользователь сам задает границы групп (эмпирический и суммы) - здесь, АА и СС так же вбираются (при необходимости, т.к. можно их и не задавать) пользователем.
- те, что считают границы автоматически методом касательных - здесь я уже объяснил смысл.
2.Метод второй касательной требует комментариев, согласен, и мне не понятно почему данный вопрос не был задан ранее, т.к. метод нигде не описан и реализован мной только в Инвенторе.

Как видно из рисунка, мы сначала делам кривую методом первой касательной (получаем точки 1 и 2). Затем делим касательной участок кривой 02 - получаем точку 3 - это граница группы А. Далее делим касательной участок кривой от точки 3 до конца кривой - получаем точку 4 - это граница группы В. Если разделить участки А и С касательными, то получим границы групп АА и СС.
Данный метод я придумал сам и использую его в случае, если объектов очень много и кривая пологая для того, чтобы сконцентрировать усилия на главном при дефиците ресурсов.
Простыми словами: выкидываем все "не важное", из остального выделяем "наиболее важное". Затем все, кроме "наиболее важного" делим на 2 группы. Вот и все.
█ 23.08.2010 15:26
Цитата:
1. Извини, затупил... administrator
- те, в которых пользователь сам задает границы групп (эмпирический и суммы) - здесь, АА и СС так же вбираются (при необходимости, т.к. можно их и не задавать) пользователем.
- те, что считают границы автоматически методом касательных - здесь я уже объяснил смысл.
2.Метод второй касательной требует комментариев, согласен, и мне не понятно почему данный вопрос не был задан ранее, т.к. метод нигде не описан и реализован мной только в Инвенторе.
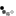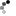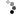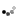
Как видно из рисунка, мы сначала делам кривую методом первой касательной (получаем точки 1 и 2). Затем делим касательной участок кривой 02 - получаем точку 3 - это граница группы А. Далее делим касательной участок кривой от точки 3 до конца кривой - получаем точку 4 - это граница группы В. Если разделить участки А и С касательными, то получим границы групп АА и СС.
Данный метод я придумал сам и использую его в случае, если объектов очень много и кривая пологая для того, чтобы сконцентрировать усилия на главном при дефиците ресурсов.
Простыми словами: выкидываем все "не важное", из остального выделяем "наиболее важное". Затем все, кроме "наиболее важного" делим на 2 группы. Вот и все.
Цитата:
1. Не понял вопроса. Все 4 реализованных метода делятся на: VVY 1. Андрей, наверное, в пояснение к каждому методу нужно описать как выбираются границы к АА и СС (я так понимаю, что ты описал только метод касательных в своем ответе).
2. Также, наверное, нужно написать что такое метод первой касательной и второй касательной в пояснении.
2. Также, наверное, нужно написать что такое метод первой касательной и второй касательной в пояснении.
- те, в которых пользователь сам задает границы групп (эмпирический и суммы) - здесь, АА и СС так же вбираются (при необходимости, т.к. можно их и не задавать) пользователем.
- те, что считают границы автоматически методом касательных - здесь я уже объяснил смысл.
2.Метод второй касательной требует комментариев, согласен, и мне не понятно почему данный вопрос не был задан ранее, т.к. метод нигде не описан и реализован мной только в Инвенторе.
Как видно из рисунка, мы сначала делам кривую методом первой касательной (получаем точки 1 и 2). Затем делим касательной участок кривой 02 - получаем точку 3 - это граница группы А. Далее делим касательной участок кривой от точки 3 до конца кривой - получаем точку 4 - это граница группы В. Если разделить участки А и С касательными, то получим границы групп АА и СС.
Данный метод я придумал сам и использую его в случае, если объектов очень много и кривая пологая для того, чтобы сконцентрировать усилия на главном при дефиците ресурсов.
Простыми словами: выкидываем все "не важное", из остального выделяем "наиболее важное". Затем все, кроме "наиболее важного" делим на 2 группы. Вот и все.
2. Ну ты выдумщик :D
█ 23.08.2010 15:38
Цитата:
Каждый метод анализа, даже самый эффективный, был изначально чьей-то выдумкой. VVY 2. Ну ты выдумщик :D
Зачем использовать чужое, когда можно придумать свое, более эффективное. ;)
█ 08.09.2010 13:53
Андрей, привет!
Я признатся в логистике не специалист. Я занимаюсь различной аналитикой, используюя SQL работаю с базами данных. Сегментации там всякие, продажи. Единственная пересекающаяся тема - прогнозирование. Достаточно времени уделил этой теме переписывал несколько методов в матлаб. Логистика для меня скорее интересное увлечение. Поэтому, возможно, часть предположений будет делитантскими :)
Во время знакомства с расчётом страховых запасов основная идея была: определение среднего и СКО. Далее, зная плечо и СКО отгрузок, расчитать комбинированное СКО = (mq2*?L2 + ?q2* mL ) ^1/2 . И последний шаг домножить СКО на коэффициент необходимого уровня сервиса. Это вариант для нормального распределения (пример во вложении-лист пример). Применение там коэффициента, коорый домножается по уровню сервиса вполне понятен. Здесь у меня вопросы:
1. Когда отклонение определяется, как Прогноз-Факт - можно ли применять такой подход? Ведь прогноз = тренд+сезон+ошибка. И далеко не факт, что ошибка распределена нормально.
2. В надстройке стоит ошибка прогноза продаж в % - почему? Может вводить фактические и прогноз и рассчитывать именно отклонение не в %-х, а как аналог СКО? Ведь получается страховой запас не зависит от самих данных по продажам? По крайней мере при вводе данных нигде нет ввода статистики.
3. Какой именно % ошибки прогноза я должен указать? Я сделал прогноз по нескольким трендам, по ним расчитал ошибку, как Корень из ( (факт-прогноз)^2) по каждому месяцу потом проссумировал и разделил на кол-во месяцев. То есть нашёл среднюю ошибку. Этот процент указать? (тоже вложение лист прогноз)
4. Правильно ли я использовал расчёт страхового запаса (вложение лист прогноз)?
5. На том же листе я рядом с расчётом инвентора попробовал посчитать страховой вручную. Для этого посчитал среднюю ошибку (Факт-План) и СКО (предположив, что после выявления тренда и сезонности оставшаяся ошибка должна быть распределена близко к нормальному распределению). Поскольку прогноз в месяцах, то и период поставил в свою формулу в месяцах. Результат немного ниже. С чем это связано? Может добавить и этот метод? ( я пока знакомлюсь с твоей статьёй)
Я признатся в логистике не специалист. Я занимаюсь различной аналитикой, используюя SQL работаю с базами данных. Сегментации там всякие, продажи. Единственная пересекающаяся тема - прогнозирование. Достаточно времени уделил этой теме переписывал несколько методов в матлаб. Логистика для меня скорее интересное увлечение. Поэтому, возможно, часть предположений будет делитантскими :)
Во время знакомства с расчётом страховых запасов основная идея была: определение среднего и СКО. Далее, зная плечо и СКО отгрузок, расчитать комбинированное СКО = (mq2*?L2 + ?q2* mL ) ^1/2 . И последний шаг домножить СКО на коэффициент необходимого уровня сервиса. Это вариант для нормального распределения (пример во вложении-лист пример). Применение там коэффициента, коорый домножается по уровню сервиса вполне понятен. Здесь у меня вопросы:
1. Когда отклонение определяется, как Прогноз-Факт - можно ли применять такой подход? Ведь прогноз = тренд+сезон+ошибка. И далеко не факт, что ошибка распределена нормально.
2. В надстройке стоит ошибка прогноза продаж в % - почему? Может вводить фактические и прогноз и рассчитывать именно отклонение не в %-х, а как аналог СКО? Ведь получается страховой запас не зависит от самих данных по продажам? По крайней мере при вводе данных нигде нет ввода статистики.
3. Какой именно % ошибки прогноза я должен указать? Я сделал прогноз по нескольким трендам, по ним расчитал ошибку, как Корень из ( (факт-прогноз)^2) по каждому месяцу потом проссумировал и разделил на кол-во месяцев. То есть нашёл среднюю ошибку. Этот процент указать? (тоже вложение лист прогноз)
4. Правильно ли я использовал расчёт страхового запаса (вложение лист прогноз)?
5. На том же листе я рядом с расчётом инвентора попробовал посчитать страховой вручную. Для этого посчитал среднюю ошибку (Факт-План) и СКО (предположив, что после выявления тренда и сезонности оставшаяся ошибка должна быть распределена близко к нормальному распределению). Поскольку прогноз в месяцах, то и период поставил в свою формулу в месяцах. Результат немного ниже. С чем это связано? Может добавить и этот метод? ( я пока знакомлюсь с твоей статьёй)
█ 09.09.2010 03:22
Привет, Дима!
Спасибо за интересный и содержательный вопрос, это для нашего форума пока редкость, как, впрочем, и знание математики.
Вообще, я стараюсь не погружаться в дебри математики и статистики, а прежде всего оценить ситуацию с позиции логики и здравого смысла (я называю это арифметикой здравого смысла), а уж потом применять математику. И это дает свои плоды: почти любую задачу можно решить арифметически, не прибегая к статистике и математике (ниже я покажу это на твоем примере прогноза). Сама надстройка создавалась для массового использования, если бы я наворотил в ней больше математики, то она стала бы не понятной для 95% ее потенциальных пользователей, и при этом эффективность инструмента осталась бы на прежнем уровне.
В общем, твои рассуждения и расчеты никак нельзя назвать дилетантскими. Хороший уровень.
Но таких, как ты - не более 5%, именно поэтому я не вижу смысла включать в массовый инструмент более сложные функции при том, что их эффективность одинакова, а учитывая сложность и временные затраты... ну ты же понимаешь :)
Вот пример: из твоего файла оптимальный прогноз из всех математических методов дает метод "обратная_Mult". Абсолютно такой же результат дает применение формулы прогноза СрСез1МесТ из моего Инвентора. Прошу заметить, что это арифметическая формула! Графики прогнозов совпадают почти на 100%. А если нет разницы, то зачем платить больше?! :D
Спасибо за интересный и содержательный вопрос, это для нашего форума пока редкость, как, впрочем, и знание математики.
Цитата:
Все верно, это стандартная формула Бауэрсокса. Формула, предлагаемая мной, является модифицированной формулой Бауэрсокса для расчета страхового запаса во временных единицах измерения. В работе это всегда удобнее. Дмитрий_Л Во время знакомства с расчётом страховых запасов основная идея была: определение среднего и СКО. Далее, зная плечо и СКО отгрузок, расчитать комбинированное СКО = (mq2*?L2 + ?q2* mL ) ^1/2 . И последний шаг домножить СКО на коэффициент необходимого уровня сервиса. Это вариант для нормального распределения (пример во вложении-лист пример).
Цитата:
Действительно, все формулы страхового запаса, которые я встречал, предполагают нормальное распределение. Использование для расчета ошибки прогноза значений прогноз/факт считаю наиболее правильным, т.к. нет более точного способа определить правильность прогноза, чем сравнить его с фактическими значениями. Что касается нормальности распределения ошибки - вопрос спорный. В тех случаях, когда я это просчитывал - получал распределение нормальное или близкое к нему. Поэтому, я принимаю это как аксиому, т.к. просчитывать это в каждом конкретном случае нецелесообразно. В действительности встречаются и более "вопиющие" с точки зрения математики недоразумения, например, использование степеней свободы при расчете дисперсии в коэффициенте вариации XYZ - анализа: согласно математике нужно использовать вариант для выборки, а на практике вопрос становится спорным и на мой взгляд более адекватный результат дает вариант для генеральной совокупности. Дмитрий_Л 1. Когда отклонение определяется, как Прогноз-Факт - можно ли применять такой подход? Ведь прогноз = тренд+сезон+ошибка. И далеко не факт, что ошибка распределена нормально.
Вообще, я стараюсь не погружаться в дебри математики и статистики, а прежде всего оценить ситуацию с позиции логики и здравого смысла (я называю это арифметикой здравого смысла), а уж потом применять математику. И это дает свои плоды: почти любую задачу можно решить арифметически, не прибегая к статистике и математике (ниже я покажу это на твоем примере прогноза). Сама надстройка создавалась для массового использования, если бы я наворотил в ней больше математики, то она стала бы не понятной для 95% ее потенциальных пользователей, и при этом эффективность инструмента осталась бы на прежнем уровне.
Цитата:
Статистика должна быть оценена еще до ввода значения ошибки в формулу. Включать же в качестве аргумента в формулу страхового запаса статистику прогноз/факт я посчитал излишним, т.к. уверен, что в большинстве случаев этот коэффициент вообще будет определяться экспертно. Дмитрий_Л 2. В надстройке стоит ошибка прогноза продаж в % - почему? Может вводить фактические и прогноз и рассчитывать именно отклонение не в %-х, а как аналог СКО? Ведь получается страховой запас не зависит от самих данных по продажам? По крайней мере при вводе данных нигде нет ввода статистики.
Цитата:
Да, этот процент. Ты используешь СКО, я же в данном случае использую медиану. Вопрос опять же сводится к применимости и эффективности. Математики будут спорить, что нужно считать СКО. Я же утверждаю, что эффективнее на практике использовать более простые показатели: медиану, моду, среднее. Безусловно, твой вариант имеет право быть. Дмитрий_Л 3. Какой именно % ошибки прогноза я должен указать? Я сделал прогноз по нескольким трендам, по ним расчитал ошибку, как Корень из ( (факт-прогноз)^2) по каждому месяцу потом проссумировал и разделил на кол-во месяцев. То есть нашёл среднюю ошибку. Этот процент указать? (тоже вложение лист прогноз)
Цитата:
Да, все верно. Дмитрий_Л 4. Правильно ли я использовал расчёт страхового запаса (вложение лист прогноз)?
Цитата:
Результат отличается всего на 3%. Данная погрешность укладывается в то, что в моей формуле используется среднее количество дней в месяце - 30,5, а так же в то, что в моей формуле при расчете используется прогнозное значение, а в твоей же - весь расчет только вокруг имеющейся статистики. administrator 5. На том же листе я рядом с расчётом инвентора попробовал посчитать страховой вручную. Для этого посчитал среднюю ошибку (Факт-План) и СКО (предположив, что после выявления тренда и сезонности оставшаяся ошибка должна быть распределена близко к нормальному распределению). Поскольку прогноз в месяцах, то и период поставил в свою формулу в месяцах. Результат немного ниже. С чем это связано? Может добавить и этот метод? ( я пока знакомлюсь с твоей статьёй)
В общем, твои рассуждения и расчеты никак нельзя назвать дилетантскими. Хороший уровень.
Но таких, как ты - не более 5%, именно поэтому я не вижу смысла включать в массовый инструмент более сложные функции при том, что их эффективность одинакова, а учитывая сложность и временные затраты... ну ты же понимаешь :)
Вот пример: из твоего файла оптимальный прогноз из всех математических методов дает метод "обратная_Mult". Абсолютно такой же результат дает применение формулы прогноза СрСез1МесТ из моего Инвентора. Прошу заметить, что это арифметическая формула! Графики прогнозов совпадают почти на 100%. А если нет разницы, то зачем платить больше?! :D

█ 09.09.2010 10:15
Ну что сказать... Инвентор очень серьёзная штука, тебе респект. Как бы сказали в Ростове: "Ты реальный пацан" :lol: Что-то могущее делать прогнозы и аналитику стоят безумных денег. А я ведь искал именно эту штуку несколько лет назад!!!
И вообще советую тебе её разместить на маркетинговых форумах - половина функций там будет очень актуальна. Например, ценообразование ведь тоже можно делать, используя АВС анализ.
И вообще советую тебе её разместить на маркетинговых форумах - половина функций там будет очень актуальна. Например, ценообразование ведь тоже можно делать, используя АВС анализ.
█ 09.09.2010 10:21
Цитата:
Спасибо, Дима. Дмитрий_Л Ну что сказать... Инвентор очень серьёзная штука, тебе респект. Что-то могущее делать прогнозы и аналитику стоят безумных денег. А я ведь искал именно эту штуку несколько лет назад!!!
И вообще советую тебе её разместить на маркетинговых форумах - половина функций там будет очень актуальна. Например, ценообразование ведь тоже можно делать, используя АВС анализ.
И вообще советую тебе её разместить на маркетинговых форумах - половина функций там будет очень актуальна. Например, ценообразование ведь тоже можно делать, используя АВС анализ.
Рад, что моя работа, действительно, полезна.
Я с радостью размещу надстройку на таких форумах, если у тебя есть стоящие площадки - кинь мне в личку адреса.
Спасибо!
█ 13.09.2010 03:51
Мне на почту поступил вопрос:
Вопрос заключается в исходном массиве данных. В нем позиции должны находиться не в иерархии (т.е. не должно быть промежуточных итогов). Если у вас есть трудность с выгрузкой из 1С "правильного" массива или есть необходимость в определенном порядке расположения номенклатуры для удобства анализа, то вы можете выгрузить номенклатуру в иерархии, далее удалить структуру (данные - удалить структуру) и воспользовавшись функцией Inventora "Сортировка по спецсвойствам", удалить промежуточные итоги из массива. После этого можно проводить АВС-XYZ анализ и ваши данные остаются организованными "удобным" для вас способом.
Цитата:
Думаю, что данная тема может быть полезна многим. ...при проведении АВС-анализа получается что в группу А попадают итоги по группам номенклатуры...
Вопрос заключается в исходном массиве данных. В нем позиции должны находиться не в иерархии (т.е. не должно быть промежуточных итогов). Если у вас есть трудность с выгрузкой из 1С "правильного" массива или есть необходимость в определенном порядке расположения номенклатуры для удобства анализа, то вы можете выгрузить номенклатуру в иерархии, далее удалить структуру (данные - удалить структуру) и воспользовавшись функцией Inventora "Сортировка по спецсвойствам", удалить промежуточные итоги из массива. После этого можно проводить АВС-XYZ анализ и ваши данные остаются организованными "удобным" для вас способом.
Часовой пояс GMT +3, время: 11:51.
Форум на базе vBulletin®
Copyright © Jelsoft Enterprises Ltd.
В случае заимствования информации гипертекстовая индексируемая ссылка на Форум обязательна.
Copyright © Jelsoft Enterprises Ltd.
В случае заимствования информации гипертекстовая индексируемая ссылка на Форум обязательна.